The Best, Worst, and Most Interesting Moments from my Marathon Month of Technical Interviews

I'm passionate about architecting and building scalable software systems.
Since I shared my story on the lessons I learned from doing 60+ technical interviews in 30 days, quite a good number of folks have reached out to me on Twitter and on LinkedIn with many questions.
Some of the questions I got include:
“How is it possible to do that many interviews in such a short time?”
“How do you fail one interview and immediately move forward to the next one?”
In that article, I briefly touched on the experiences that formed my motivation for going on that intense run of technical interviews. I also shared lessons I learned from that experience and, thankfully, they’ve turned out to be useful to a lot of people around the world.
What I hadn’t shared yet were specific examples of some of the things I encountered during this period. In this article, I’ll get into some of those details by sharing the most eventful moments during my marathon month of technical interviews – including technical content and personal experiences.
The technical content will focus more on the most challenging algorithmic questions, projects, and coding challenges I faced, while the personal part will be about my experiences — successes, struggles, etc – and the lessons I extracted from these eventful moments. I hope in this you, dear readers, can find something useful to apply to your professional lives.
Navigating the introductory phone call I was least prepared for
At the time I started interviewing, I had a full-time, non-remote day job as a software engineer with a company in the San Francisco Bay Area. That means I had a busy work schedule, typical of any software engineer.
On one particular day, I had just finished from a technical meeting and got on this call with a recruiter from a certain mid-size technology company based in Palo Alto, California. I joined that call straight out of a meeting and because of that, I didn’t have the time to do proper research on the company – or at least that’s what I told myself.
The phone call turned out to be not so introductory, rather it seemed to be a mini technical interview. Not only was I asked about my experience and some of the projects I had worked on, I was also asked to explain some technical concepts. Some of the concepts I vividly remember include:
- Closures in JavaScript
- Concurrency and lock-mechanisms
- Difference between hashing and encryption
All in an introductory phone interview? Yes, my friend.
Even though I attempted to answer all of these questions, I wasn’t very coherent in my answers. In addition, the fact that I didn’t do my research on the company before the call didn’t help, as I couldn’t ask a lot of insightful questions about the company and couldn’t also give a good answer when the interviewer asked what I knew about the company.
Some of the lessons I took out of that experience are to never get on a phone call with an interviewer without knowing at least these two things:
- The first name of your interviewer
- At least one tangible thing about the company — what they do, where they are located, any recent news, something
The other thing I’ll say is when you are asked questions that you weren’t expecting, try to stay composed and make an attempt at answering them to the best of your knowledge. And if you don’t know about it, it’s okay to say you don’t.
Tackling the most challenging algorithm question
Over the course of my interviewing period, I encountered some challenging algorithmic questions ranging from dynamic programming problems to problems where I used Dijkstra’s Shortest Path algorithm.
The one algorithmic problem, however, that still stands out to me as the most challenging was a problem that involved constructing words from a 2-D array. Below is the problem statement:
Given a 2-D board and a list of words from the dictionary, find all words in the board that are contained in the list. Each word is formed by sequentially adding characters in adjacent cells, whether horizontally or negatively and no character in a cell should be used more than once in a word.
The problem statement written in JavaScript code is seen below:
My approach in solving this problem is outlined in the steps below:
- Build a Trie using the words in listOfWords.
- Using a combination of recursion and backtracking, explore each cell in the 2-D array starting with the first cell to see if its character matches the first character of any word in the Trie data structure.
The image below highlights characters in the matching cells that match the words in the Trie.
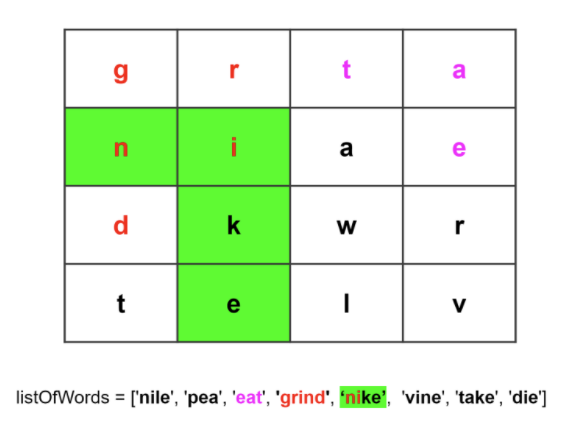
As seen in the image above, the subset of words in listOfWords that can be formed from the characters in the 2-D array are eat, grind, and nike.
For more details about this problem and the Trie data structure, I’ve added some links in the resource section at the end.
Getting a little too ambitious on a take-home project
I got about 18 take-home “expect-to-spend-5-hours” projects for the period I was on this interviewing marathon. As I mentioned in my first article, one of the companies offered to pay $68/hour to candidates working on their take-home projects. (I wish I could say that was the project I found most interesting.)
The project I found most interesting was one where I was asked to build a font-scraper service. The requirements for this service was such that it would provide an endpoint that accepts a source URL, access the page at that URL, and extract all the fonts on the page set via inline, internal, and external styles. In addition, the service would access every outgoing URL found as a link on the source page, extract fonts from all those pages, and keep doing this recursively.
In addition to the requirements above, the service was meant to be configurable such that the consumer of the service could pass two parameters:
- A crawlType param that determines how the pages would be traversed using either bread first search or depth first search
- A pageLimit param that determines how many pages should be explored. (Interesting stuff!)
This project tested everything from knowledge of good system architecture and API design to my decision-making – especially as it concerns structuring a project – and from code readability to code extensibility. It was a very well-thought-out project.
Some of the good things I did on this project were:
- Unit/Integration tests (more than 700 lines of code with ~90% coverage)
- Implemented rate limiting. (This wasn’t part of the requirements but if you’re building APIs, you should be thinking about this)
- Implemented some form of queuing system for handling failed scrape jobs. (Again this wasn’t part of the requirements but hey, why not?)
The one thing I did wrongly that cost me dearly was I wrote the font-parsing algorithm to extract the CSS from the HTML myself. Because I love to solve problems from first-principles, I was ambitious and wanted to tackle this head-on. Bad move!
It’s important to know when to express your love for challenges; doing that in an interview may not always be the best idea. If you’re going to reinvent the wheel, make sure your wheel is better. I could have just gone with a library that already solved that problem.
For take-home projects, spend time on the core requirements and make sure those work before moving on to extra requirements. I learned that the hard way, you don’t have to.
Solving a Tricky System Design Question
I was asked to build an interactive shell that allows access to a transactional in-memory key/value store.
The shell would accept the following commands:
- SET [key] [value]: Sets the given key to the specified value. If the key is already present, overwrite the old value.
- GET [key]: Prints out the current value of the specified key. If the key has not been set, it prints a default message.
- DELETE [key]: Deletes the given key. If the key has not been set, ignore.
- COUNT [value]: Returns the number of keys that have been set to the specified value. If no keys have been set to that value, prints 0.
- BEGIN: Starts a transaction. These transactions allow you to modify the state of the system and commit or rollback your changes.
- COMMIT: Commits the changes made within the context of the active transaction and ends the active transaction.
- ROLLBACK: Throws away changes made within the context of the active transaction and ends the active transaction. If no transaction is active, prints NO TRANSACTION
Implementing the SET, GET, DELETE and COUNT commands didn’t seem difficult. The trickiness was in implementing the abstraction that would represent a transaction.
A transaction is created with the BEGIN command and creates a context for the other operations to happen. For example if the following sequence of commands were entered in the interactive shell
> BEGIN //Creates a new transaction
> SET X 5
> SET Y 19
> GET Y
Y = 19
The expectation was that a transaction would be created (because of the BEGIN command) and all the following operations would happen and work as they should. However, they would work only in the context of that transaction that was created. This transaction would be the active transaction.
It is also expected that until the active transaction is committed using the COMMIT command, those operations do not persist, and the ROLLBACK command throws away changes made by those operations in the context of the active transaction.
The snippet below provides more clarity about the expected behavior:
> BEGIN //Creates a new transaction which is currently active
> SET X 5
> SET Y 19
> GET Y
Y = 19
> ROLLBACK //Throws away the changes made
> GET Y
Y not set // Changes made by SET Y 19 have been discarded
The trickier part of this question was understanding that each transaction could spawn a new transaction (think of it as a child transaction).
The newly spawned transaction inherits the context (variables) from its parent transaction and changes made in the context of a child transaction and committed would reflect in the parent transaction because committing wrote directly to the key/value store.
Here is another sequence of operations that explains this better:
> BEGIN //Creates a new transaction which is currently active
> SET X 5
> SET Y 19
> BEGIN //Spawns a new transaction in the context of the previous transaction and now this is currently active
> GET Y
Y = 19 //The new transaction has access to the context of its parent transaction
> SET Y 23
> COMMIT //Y's new value has been persisted to the key-value store
> GET Y
Y = 23 // Changes made by SET Y 19 have been discarded
This question tested everything from understanding of good system design, knowledge of data structures – especially for designing the abstraction that represented a Transaction – and how to write highly performant code.
Handling the most hurtful failure
Doing 60+ technical interviews in such a short time meant I had a good dose of failures, all coming at a really fast pace. Some I could shake off easily, a few others would hit at the core of my sanity and make me question how good a software engineer I was. Those latter ones were harder to shake off.
The one that turned out to be the most hurtful failure, and I still vividly remember it, came during an interview with a data infrastructure firm headquartered in Denver. The company was looking to fill a senior software engineer position and they reached out to me because they thought I was a good fit.
The introductory call went well, the first technical interview went even better, but it was the second technical interview that went south. I was asked to write a function that took in a list of times and calculated the minimum time difference between different times.
One reason why this hurt really bad was because I know I solved the problem correctly, and even the interviewer confirmed it. I had identified the boundary conditions and ensured that the code I wrote handled those conditions and other edge cases. I even went on to ask the interviewer if I should care about cases where the time string was wrongly formatted (12.30 for example vs 12:30). With such a bullseye, then, did I move on to the on-site?
It’s one thing to not pass an interview because you didn’t do well, but to do well and still not pass the interview? I couldn’t wrap my head around that. I remember the day I got that rejection email. I was so devastated that I had to reschedule the remaining interviews I had that day.
After much thought, I had to accept that sometimes the reason you don’t scale an interview may not be you; there could be myriad of other reasons, from a change in company’s hiring plans, an interviewer having a bad day, etc.
That experience taught me that there are things I can control and there are things I can’t. You can control how well you do in the interview, the quality of the code you write, how well you communicate your thought process, etc. One thing you can’t control is the outcome – you can only hope that the things you can control, your actions, can influence the outcome.
So separate yourself from “failed” interviews. When the failures come, seek to take the best lessons out from them and apply it to your next interview. In other words, fail forward.
Celebrating my biggest win
Going through 60+ technical interviews in 30 days definitely had more downs than ups. However, when the wins started coming, it was very exciting and fulfilling.
Whether the win was as small as passing a technical phone-screen or a HackerRank coding challenge, or as big as getting to an on-site interview or even the many offers that came, I learned to celebrate every win.
And it was in celebrating all these wins that I discovered the biggest win of all: By going through this exercise, I had grown immensely and I had become more confident in handling technical interviews. That truly was my biggest win!
Sounds like a simple answer, but it’s the truth.
To you
You may not embark on a technical interviewing marathon like I did, but most definitely you are facing your own daily challenges as you strive to be better every day. Progress is sure when you’re consistent. Keep plugging away and the wins will come.
I sincerely hope reading about my experiences has been rewarding to you, but more importantly, I hope you have taken away vital lessons that you can apply to your professional and personal lives. I wish you the very best in your career!
I’ll be writing a series on data structures in a few weeks where I’ll be explaining how to know what data structure to use when designing an algorithm. If that’s something you’re interested in, please follow me on Twitter where I post about my articles.
Also, if you ever need someone to do a mock interview with you, I’ll be more than happy to — free to reach out to me on Twitter @meekg33k.
E go be ✌️




