3 times I used my knowledge of data structures on the job

I'm passionate about architecting and building scalable software systems.
In the second half of 2020, I held numerous free mock technical interviews. During those interviews, one recurring question I often got from the interviewees was:
"I know I need data structure knowledge to pass most technical interviews, but how much am I going to need it for my day-to-day job?"
My answer to them was mostly: "It depends on what kinds of problems you want to solve".
As engineers starting out get to know, there's no shortage of companies who use seemingly highfalutin computer science subject matter to vet engineering candidates, even if it's sometimes hard to draw a direct relevance from it to the specific job being interviewed for.
But in this article, I will get into a few examples where I have, in fact, put my data structure knowledge to good use on the job.
TLDR: I hope I can convince you, in the same way I try with my mock interviewees, that the knowledge of data structures is important – yes for acing that technical interview, but moreso to help you a become a better software engineer in practice.
Let’s jump right in!
Optimizing the page load time of a web application
I was involved in a project where we were building an in-memory caching layer for a micro-service that served learning content data to users via a web application.
The schema structure for the service started out with three main entities, each identifiable by an unique id, among other metadata:
- Classes
- Subjects
- Modules
The relationship between the entities was such that a Class could have one or more Subjects (1 to N relationship) and a Subject could have one or more Modules.
A simple entity-relationship diagram showing the relationship between a single Class entity and the other entities would be as shown below:
Given that there are more than one Class entities, what we would have is a forest of trees with the Class entities as the root nodes. Representing this in code using JSON format would be something like the code snippet below:
Imagine there is a request to get all the modules for a specific Class id. Given this structure, the pseudo-code for that logic would be something like:
- Iterate through the list of classes to find the Class that matches the Class id.
- Look up to find the list of subjects in the Class.
- Iterate through the subjects from step 2 and get a list of the modules in each Subject.
- Merge the list of modules for each Subject gotten from step 3 into one list.
This is an example of a request type that typically slowed down the render time of the web application. It became worse when we added Section entity to Modules and Example entity to Sections – this resulted in a tree-like data structure up to five levels deep!
If we analyze the steps in the pseudo-code above, we can see that using a list data structure for Subjects and Modules isn’t the most optimal as lists are not best suited for search operations.
To optimize this, we did the following:
- Flattened the hierarchy such that each entity was on the same level as the other. By replacing the tree-like structure with a dictionary that stored all the entities using its id as the key and the entity data as the value, we decreased the lookup time to find an entity.
- Create a dictionary of entity categories for faster category-level access.
Resulting in a data structure that looked like something below:
This optimization significantly reduced the page load time as lookup for entity metadata was a lot faster and it allowed us to easily scale by adding more entities.
Building an auto-suggest component
If you have ever performed a search for a product to buy on Amazon where as you type in a few characters you begin to see suggestions in a drop-down, then you have used an auto-suggest component.
Building that component was another interesting example for me of where the knowledge of data structures proved to be very valuable on the job.
To build this feature, we opted to use a third-party library. Using the library came with a number of benefits including but not limited to customizable options for the user interface, ease of styling, etc. However, it also meant that we were stuck with whatever the internal implementation was.
That turned out to be our bane.
This library’s implementation of the auto-suggest feature is such that it takes in a list of possible suggestions. When a user types in a character, it would perform a search by iterating through all entries in that list of suggestions to find the suggestions that are prefixed by the characters the user typed.
This worked okay for a small number of suggestions to the list, but as the number increased, we noticed a drop in performance of the component.
To solve this problem, we created a modified component that leveraged a Trie data structure constructed from the suggestion list passed to it. Each word in the list of suggestions is broken into characters, with each node in the Trie corresponding to a single character.
For example, given a list of suggestions made up of the words 'nike', 'nil', 'pea', 'eat', 'grind', 'vine', 'take', 'die', the resulting Trie data structure from the list of words is shown below:
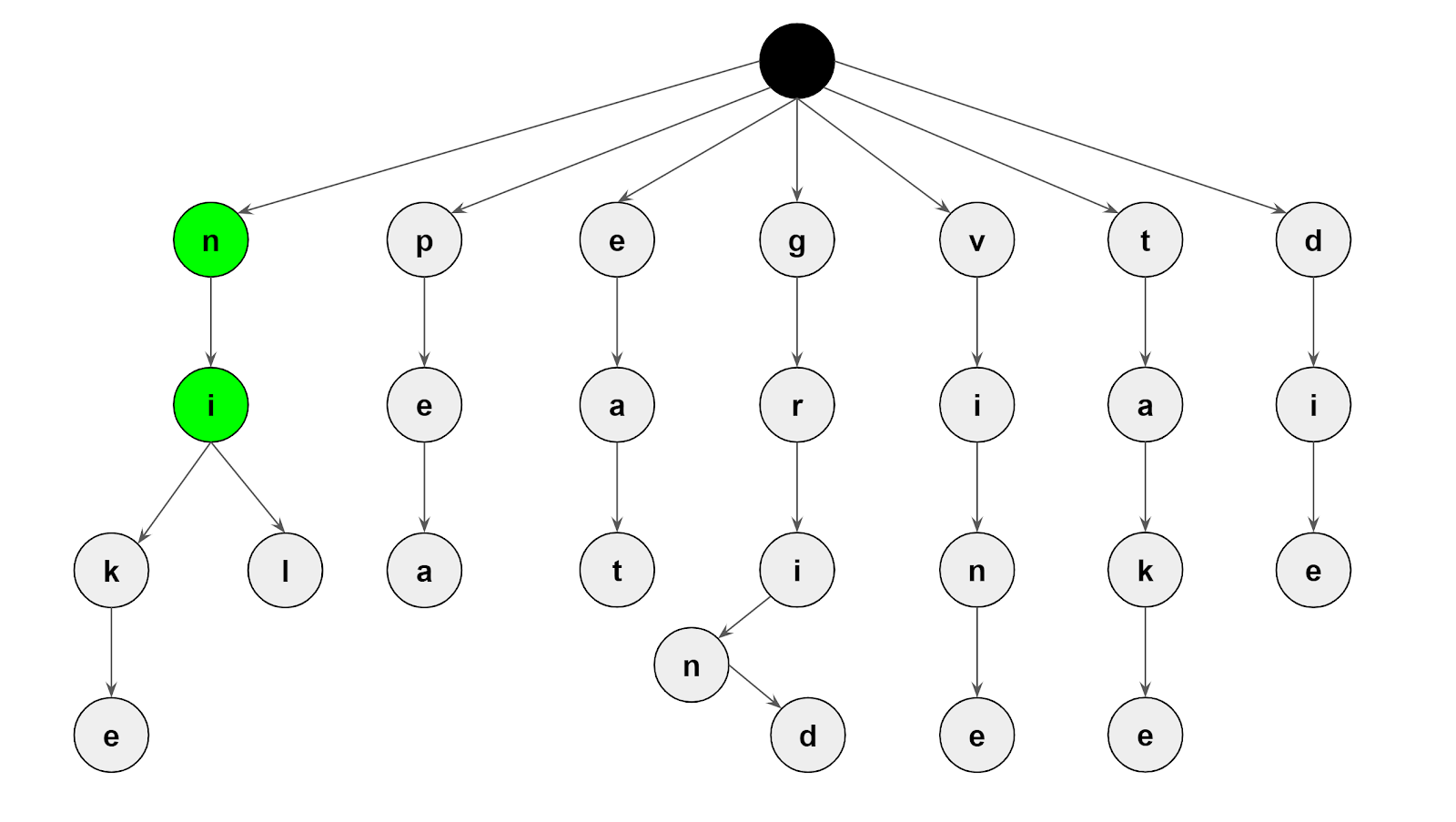
Given this Trie data structure, when a user types the word ni, it returns the suggestions nike and nil. This is because the Trie was designed such that each node in the trie has a list of words whose prefix is made of a sequence of characters in the ancestor nodes and the character in the node.
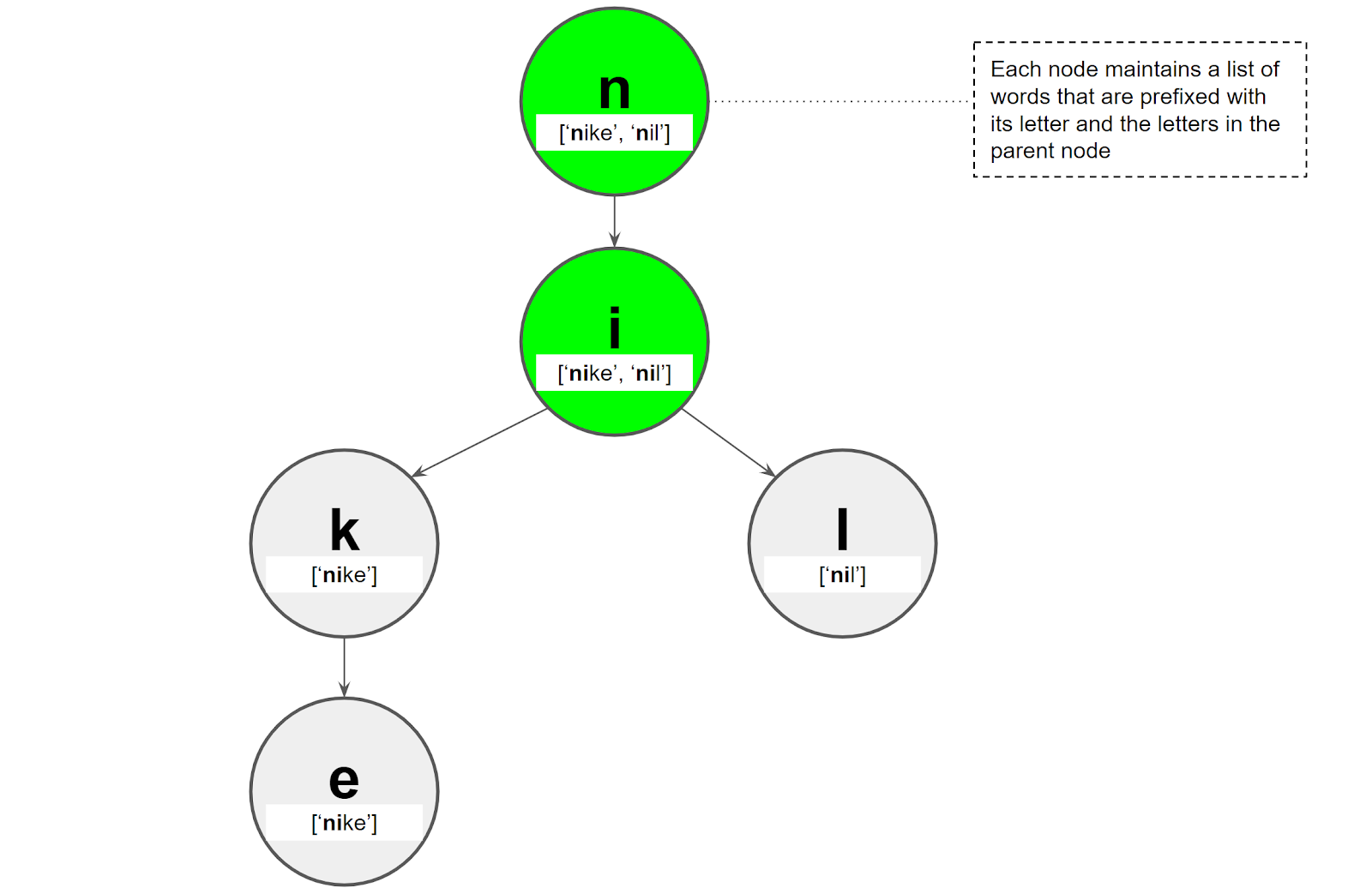
For example, the node with character i has nike and nil in its list of words because both words have n (from the ancestor node) and i (from the current node) in its prefix.
Like with all decisions there are trade-offs.
Switching our implementation to leverage a Trie data structure came with a cost. For a suggestion list with less than 1,000 words, using a Trie seemed a bit of an overkill. So the final optimization we did was to only build the Trie data structure when the list of words was more than 1,000.
Building a queue system for a bidding service
The last instance where I remember how my knowledge of data structures proved useful in the real world was for a project to build a queuing system for a bidding application.
One of the core functionalities of the application was that users could see a list of items that were up for bidding and place bids for a specific item. Each item up for bidding had a bidding window, a time-frame within which bids should be placed.
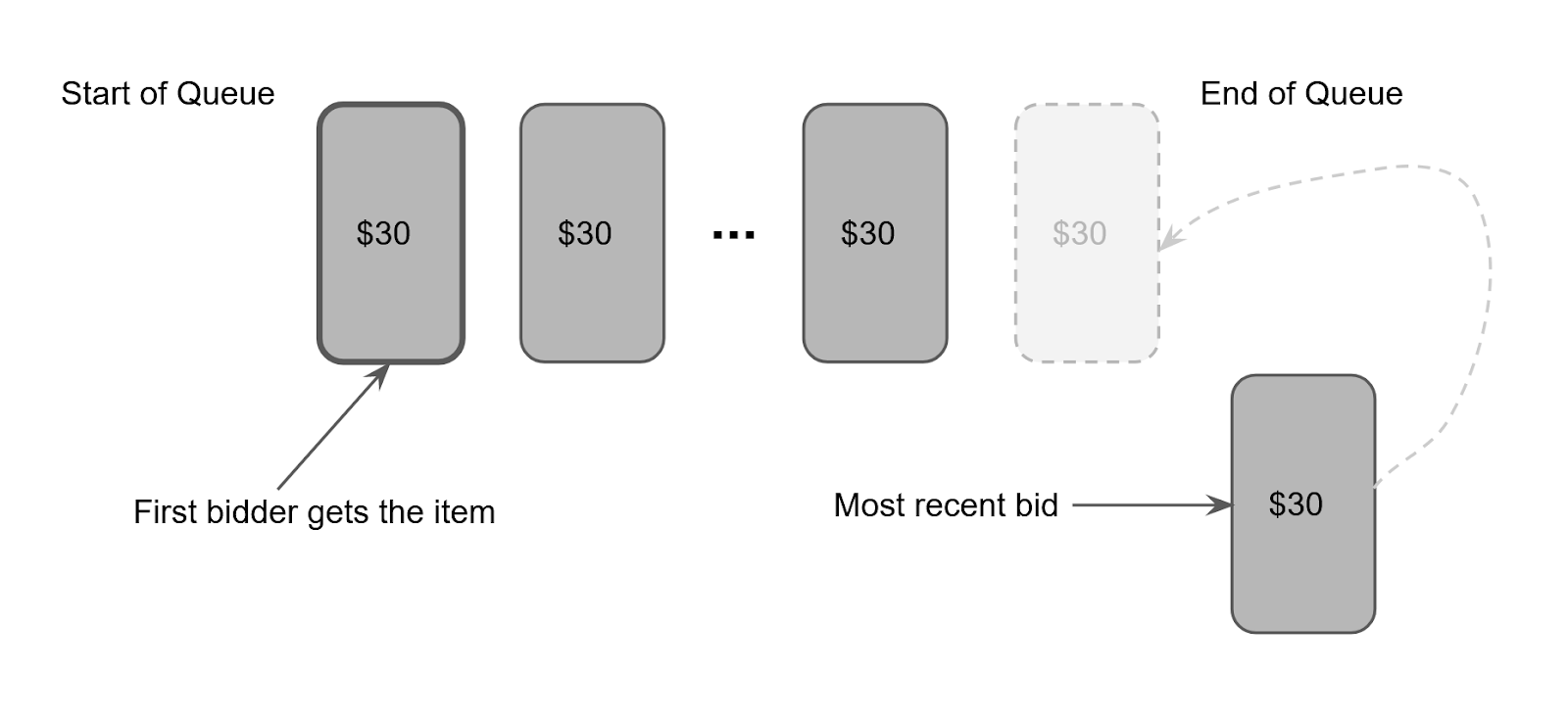
If all the bids received for a particular item of the same amount (for example $30 as shown in the image below), the item will go to the user who placed the first bid once the bidding window elapsed.
However, if different bids of varying amounts were placed for an item during the bidding window, the item would go to the highest bidder once the window ends.
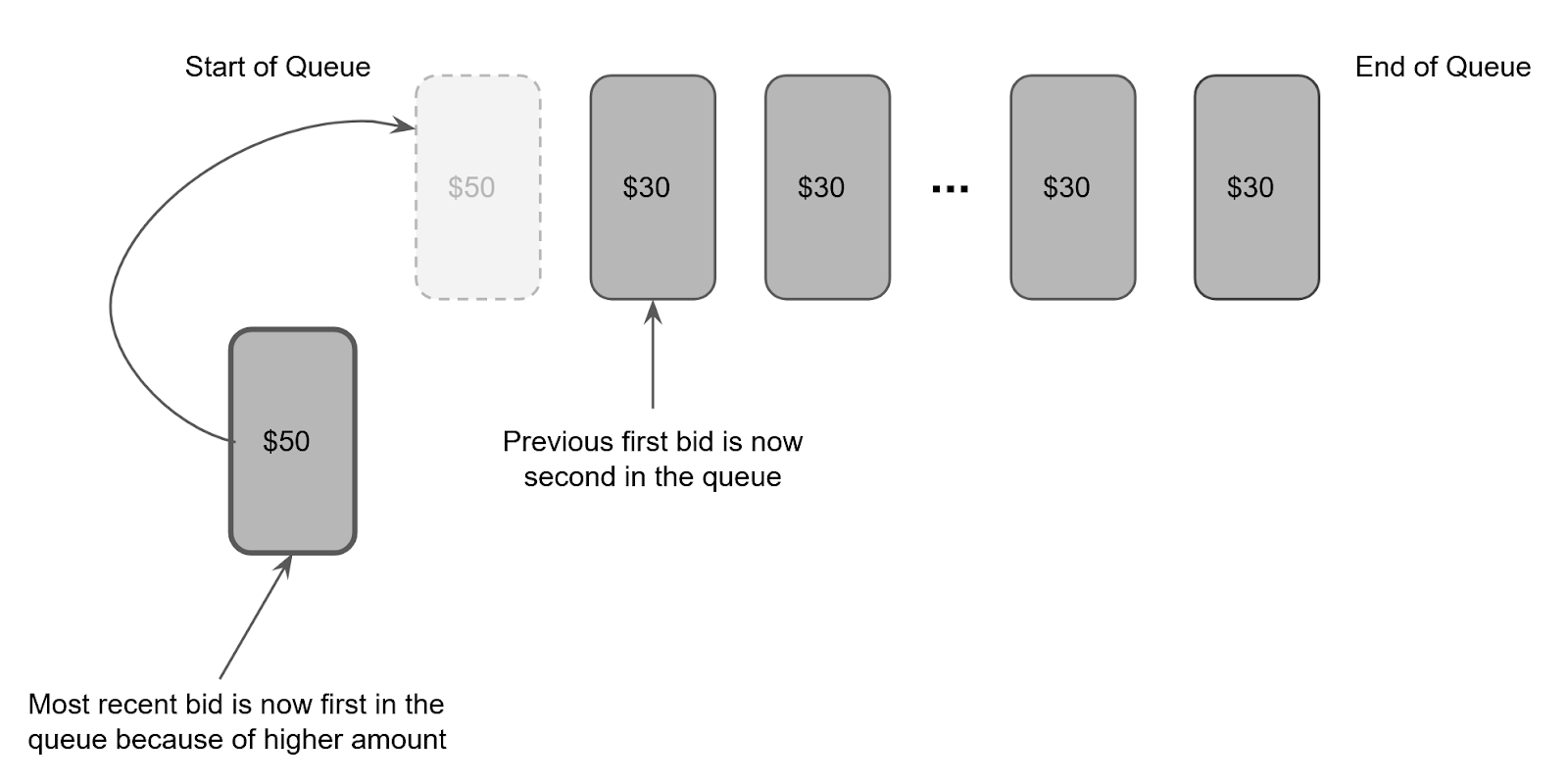
Based on the requirements, the one data structure that seemed ideal for this was the queue. The queue data structure, because of its FIFO principle, easily satisfied the requirement where the item should go to the first bidder if equal bids were received. This is because the first bid that was made during the bidding window would be at the start of the queue.
However, the system needed to take into account that for cases where different bid amounts were received for an item, at any point in time, the highest bidder should always be at the start of the queue.
Basically, it would have to sort the bids based on amount first, and then based on time of creation. These sets of requirements made the priority queue an ideal data structure for this system.
Conclusion
You may not have to use the most arcane data structures every day at your job, but having a sound knowledge of data structures is important. In short, you can think of data structures are a powerful tool in the repertoire of a software engineer to help them come to solutions faster and write cleaner, more efficient code.
So the question I'll leave you with is, "what kinds of problems are you looking to solve"?
E go be! ✌️




